
The official Android’s Guide to App Architecture recommends using Repository classes. However, in my opinion, if you follow this pattern, you’re guaranteed to end up with a dirty code.
In this article I’ll discuss the officially proposed Repository Pattern and explain why it’s actually an anti-pattern in Android applications.
Repository
The official Guide to App Architecture recommends the following structure for organizing your app’s logic:
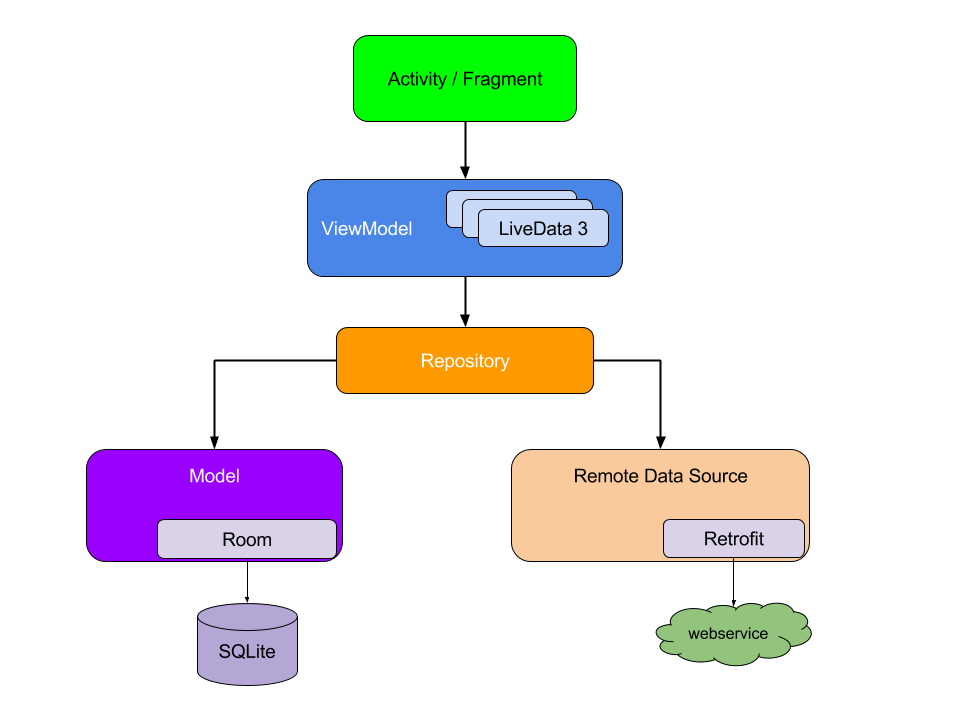
The role of Repository object in this structure is:
Repository classes are responsible for the following tasks:
- Exposing data to the rest of the app.
- Centralizing changes to the data.
- Resolving conflicts between multiple data sources.
- Abstracting sources of data from the rest of the app.
- Containing business logic.
In essence, the guide recommends using repositories to abstract out the source of the data in your app and host the business logic. Sounds very reasonable and even useful, isn’t it?
Repository in Android Architecture Blueprints v2
About two years ago, I reviewed the “first version” of Android Architecture Blueprints. It supposedly implemented a clean example of MVP, but, in practice, that blueprint turned out to be dirty codebase. It indeed contained interfaces named View and Presenter, but they didn’t establish any architectural boundaries, so it wasn’t even MVP. You can watch that code review here.
Since then, Google updated the arch blueprints to use Kotlin, ViewModel and other “modern” practices, including Repositories. These updated blueprints are called v2.
Let’s take a look at TasksRepository interface in blueprints v2:
interface TasksRepository {
fun observeTasks(): LiveData<Result<List<Task>>>
suspend fun getTasks(forceUpdate: Boolean = false): Result<List<Task>>
suspend fun refreshTasks()
fun observeTask(taskId: String): LiveData<Result<Task>>
suspend fun getTask(taskId: String, forceUpdate: Boolean = false): Result<Task>
suspend fun refreshTask(taskId: String)
suspend fun saveTask(task: Task)
suspend fun completeTask(task: Task)
suspend fun completeTask(taskId: String)
suspend fun activateTask(task: Task)
suspend fun activateTask(taskId: String)
suspend fun clearCompletedTasks()
suspend fun deleteAllTasks()
suspend fun deleteTask(taskId: String)
}
Even before reading any code, the sheer size of this interface is a red flag. This number of methods in one interface would be suspicious even in big Android projects, but we’re talking about ToDo app with just 2000 lines of code in it. How come this almost trivial app needs a class with this API surface?
Repository as God Object
The answer to the question from the previous section is in TasksRepository’s methods names. I can roughly divide the methods of this interface into three disjoint sets.
Set1:
fun observeTasks(): LiveData<Result<List<Task>>>
fun observeTask(taskId: String): LiveData<Result<Task>>
Set2:
suspend fun getTasks(forceUpdate: Boolean = false): Result<List<Task>>
suspend fun refreshTasks()
suspend fun getTask(taskId: String, forceUpdate: Boolean = false): Result<Task>
suspend fun refreshTask(taskId: String)
suspend fun saveTask(task: Task)
suspend fun deleteAllTasks()
suspend fun deleteTask(taskId: String)
Set3:
suspend fun completeTask(task: Task)
suspend fun completeTask(taskId: String)
suspend fun clearCompletedTasks()
suspend fun activateTask(task: Task)
suspend fun activateTask(taskId: String)
Now, let’s associate responsibilities with each of the above sets.
Set1 is basically an implementation of Observer pattern using LiveData facility. Set2 represents a gateway to data storage, plus two refresh methods which are needed because there is a remote data storage hiding behind repository. Set3 contains functional methods which basically implement two parts of app’s domain logic (tasks’ completion and activation).
So, there are three distinct responsibilities coupled in this single interface. No wonder it’s so big. And while an argument can be made that having Set1 and Set2 as part of a single interface is acceptable, addition of Set3 is unjustifiable. If this project would need to be developed further and become real Android app, Set3 would grow in direct proportion to the number of domain flows in the project. Oops.
We have a special term for classes that couple so many responsibilities together: God Objects. It’s a widespread anti-pattern in Android apps. Activities and Fragments are the usual suspects in this context, but other classes can grow into God Objects too.
Wait a second… I think I found a better name for TasksRepository:
interface TasksManager {
fun observeTasks(): LiveData<Result<List<Task>>>
suspend fun getTasks(forceUpdate: Boolean = false): Result<List<Task>>
suspend fun refreshTasks()
fun observeTask(taskId: String): LiveData<Result<Task>>
suspend fun getTask(taskId: String, forceUpdate: Boolean = false): Result<Task>
suspend fun refreshTask(taskId: String)
suspend fun saveTask(task: Task)
suspend fun completeTask(task: Task)
suspend fun completeTask(taskId: String)
suspend fun activateTask(task: Task)
suspend fun activateTask(taskId: String)
suspend fun clearCompletedTasks()
suspend fun deleteAllTasks()
suspend fun deleteTask(taskId: String)
}
Now the name of this interface reflects its responsibilities much better!
Anemic Repositories
At this point, you might wonder: “if I extract domain logic from repositories, will it solve the problem?”. Well, let’s get back to “arch diagram” from Google’s guide.
If you want to extract, say, completeTask methods from TasksRepository, where would you put them? According to Google’s recommended “architecture”, you’d need to pull that logic up into one of your ViewModels, . This doesn’t sound as too bad of a solution, but it actually is.
For example, imagine that you put this logic inside one ViewModel. Then, one month later, your PM wants to allow users to complete tasks from several screens (that’s the case in all ToDo managers I ever used). Logic inside ViewModels isn’t reusable, so you’ll need to either duplicate it, or push it back into TasksRepository. Obviously, both approaches are bad.
A better approach would be to extract this domain flow into a dedicated object and then insert it between ViewModel and repository. Then, different ViewModels will be able to reuse this object to execute that specific flow. These objects are known as either “use cases” or “interactors”. However, if you introduce use cases into your codebase, repositories become kind of useless boilerplate. Whatever it is that they do, will be much better accommodated by use cases. Gabor Varadi already covered this topic in this post, so I won’t go into details myself. I subscribe to pretty much everything he said about “anemic repositories”.
But why use cases are so much better than repositories? The answer is simple: use cases encapsulate individual flows. Therefore, instead of a single repository (per domain concept) which will gradually grow into God Object, you’ll have several narrowly-focused use case classes. If a flow happens to depend on both networking and persistence, you can pass the respective abstractions into use case class and it’ll “arbitrate” between these sources.
All in all, looks like the only way to prevent repositories from degrading into God Classes while avoiding unneeded abstractions is to get rid of repositories.
Repositories Outside of Android
You might be wondering now whether repositories are Google’s invention. No, they aren’t. Repository pattern had been described long before Google decided to adopt it in their “arch guide”.
For example, Martin Fowler described repositories in his book Patterns of Enterprise Applications Architecture. There is also this guest post on his blog describing the same concept. Repository, according to Fowler, is just a wrapper around persistence layer which exposes a higher-level query interface and, potentially, in-memory caching. I’d say that, in Fowler’s view, repositories behave like ORMs.
Eric Evans, in his book Domain Driven Design, also introduced repositories. He wrote:
Clients request objects from the repository using query methods that select objects based on criteria specified by the client, typically the value of certain attributes. The repository retrieves the requested object, encapsulating the machinery of database queries and metadata mapping. Repositories can implement a variety of queries that select objects based on whatever criteria the client requires.
Note that you could replace “repository” in the above quote with “Room ORM”, and it would still make perfect sense. So, in the context of Domain Driven Design, repository is ORM (implemented either manually, or using third-party framework).
As you can see, repository wasn’t invented in Android world. It’s a very reasonable design pattern that all ORM frameworks build upon. However, note what repositories are not: none of the “classics” ever argued that repositories should attempt to abstract out the distinction between network and database access.
In fact, I’m pretty sure that they’d find this idea naive and destined to fail. To understand why, you can read another article, this time by Joel Spolsky (founder of StackOverflow), titled The Law of Leaky Abstractions. Simply put: networking is too different from database access to be abstracted out without “leaking” heavily.
How Repository Became Anti-Pattern in Android
So, were these Google who misinterpreted the Repository Pattern and injected the “naive” idea to abstract out network access into it? I doubt so.
I found the earliest reference to this anti-pattern in this GitHub repo, which is, unfortunately, a very popular resource. Now, I don’t know whether this author invented this anti-pattern, but it looks like it was this repo that popularized the general idea inside Android ecosystem. Google devs probably picked it up from there, or one of its secondary sources.
Conclusion
So, repository in Android evolved to become an anti-pattern. It looks fine on paper, becomes problematic even in trivial applications and will evolve into real trouble in bigger projects.
For example, in another Google’s “blueprint”, this time for arch components, usage of repositories eventually led to pearls like NetworkBoundResource. Mind you, that GitHub Browser sample is still tiny ~2 KLOC app.
As far as I can see, “repository pattern”, as defined in the official docs, is incompatible with clean and maintainable code.
Thanks for reading and, as usual, you can leave your comments and questions below.

Yep, completely agree.
IMO (for any beginners reading) once you realise that the google’s android developers are for the most part smart beginners, or at a push experienced developers (with experience in a tangential field like embedded programming rather than application development) then everything starts to make sense. Learning to spot which bits of google “advice” you’d be better off ignoring is the most important lesson you can learn on your quest to master android development!
Android Architecture Blueprints though, what an irresponsible mess – irresponsible because many people don’t realise it’s just a repo by some people who happen to work for google, and who are learning how to do app development (while professional android developers just shake their heads)
Great article Vasiliy, I’ve burned myself many times with repositores & with trying to abstract offline and online resources inside 1 class.
Write about repositories in 2020. That’s funny.
All that was already 3-4 years earlier, even there was an article about what mistakes are better to avoid.
I hate it when authors without precise arguments take a bad implementation and try to impose their point of view.
Selective thinking, developers’ problem.
Try to write thoughtful articles instead of throwing them in without any arguments.
Some years ago I left the project more than 3 million lines of code. There was Clean, MVP.
And there were no contexts in repositories and no resources of any kind.
And even if you write an abstract on this case for some ResProvider, what is wrong with that? If it is an internal module for the Android application.
It seems that the author does not understand how to create multi-module applications, how to prepare Di, write tests and what difficulties can really be. With mapping, DTO separation and ValueObject. As CRUD is spelled, a cache is organized for local storage.
That’s if you wrote such moments and lit up the details, mb and there was a point, but so…
Forks on water.
It’s worth noting that this isn’t just “any random Repository pattern specifically chosen to be incorrect”, this is from the official Architecture-Samples repository by the Google Android Developer Advocate Team, which is supposed to serve as a basis for good architecture practices, rather than to have a
result(int resultCode)method on a Presenter.I disagree about repositories being anti pattern. They’re are supposed to be facades for data towards app domain. The implementation of the Google samples might be what you say. You still need to implement an architecture of your choosing to support uni directional flows. The Google samples are usually not that great in general because of lack of consiceness.
Thank you for this great article. I am an Android beginner, and I have often said to myself that either I am too beginner to understand things, or the Repository or the UseCase is useless because my UseCase methods were always empty (they just called the Repository methods ).
I always use the NetworkBoundResource when I have data online, and this is one of the reasons why the Repository seemed useful to me (as in the Google blueprint). So, is the following approach good: use Repository (for NetworkBoundResource) when I have data to request online (even if it will make my UseCase empty), and not use it when the data can be requested directly from the database (and there I will have useful UseCase). Or you would recommend not using Repository at all, and use the NetworkBoundResource directy in the UseCase !?
Hi Frederic,
I think there is no need for NetworkBoundResource at all. This class is basically just some variation of AsyncTask (same philosophy). I’d recommend just writing use case classes which make use of e.g. Retrofit’s APIs and Room’s DAOs, and then return a simple Result sealed class. However, each use case will have its own definition of Result (so, no “generalized” classes).
A bit of a jump to call repos an anti pattern. A misused pattern certainly. Does every app need them? No. Are they useful in some apps? Of course.
Usually I use repositories if the app requires a lot of data caching (a very good practice to get into on mobile apps). Why is caching good in repos? Caching data in the UI layer has the problem of not being reusable between screens as you mention, caching in the data layer overcomplicates the data layer, caching in the usecase layer just makes your usecases bloody complicated and gives the layer too much responsibility.
The google blueprints about repositories arn’t the best. But the pattern in itself is super useful when it’s used in the write circumstances.
all is rosy and dandy until when you want to make any small change to the classes, but then you realize : wait a minute, because of use of inheritance – instead of Composition/ interfaces – we have THREE classes which are tightly coupled together, so you can’t change anything unless you look at ALL THREE classes in combination. clean architecture is supposed to be CLEAN, doesn’t mean you tightly couple THREE CLASSES. if you must couple classes, best then to write code in ONE CLASS instead of using inheritance.
there is a GOOD REASON why Joshua Bloch said : FAVOUR COMPOSITION OVER INHERITANCE. wisdom comes with age.
I am really interested in another point of view for caching strategy and how can we encapsulate it in the repository? Could you please share some examples if you have any?
Great Article but..
1) I don’t agree at all with the generalization of repository pattern as an anti-pattern. The implementation of it maybe an anti-pattern. Those are two very distinct view points.
2) Like with everything in life that’s public facing, intent/audience is important to consider. Google’s recommendation is not geared towards the Vasiliy type, or the ubber app developers. It states clearly on the docs – while the recommendation won’t work for everyone (and if you already have something working for you – keep it) the recommendation is purely for beginners, someone who has no clue where to start or just wants a guide on structuring their app better.
You would probably agree with me here, as you start learning sh*t, the last thing in your mind is google’s-scale app practices.
If I may return to my point 1 above, repositories are really nothing more or less than controllers are in the front-end. Like controllers control access to the app, repositories control access to data.
If you believe repositories are an anti-pattern, then controllers (as in the MVC for example) are also equally an anti-pattern. Why? Because they can also get pretty blotted too. But that doesn’t stop anyone, including Vasiliy, from promoting MV(c/x) patterns.
As with controllers, time evolved and people became more experienced with the idea. Awesome patterns like action controllers emerged, which reduces blotness substentially and help to keep code base much cleaner and easier to maintain over time.
Same thing can be said/done with repositories. Nothing is stopping you or anyone from having what I call “Action Repositories”. These are repositories that are responsible for one action. They work great, they are cleaner, same pattern as recommended by Google, and stay maintainable in the long run.
So, my two pence for anyone reading this article is this, be alert when you read this article. There is nothing anti-pattern about the repository pattern. Your implementation may be. If you are new to Android, I will urge you to follow this Google’s recommendation https://developer.android.com/topic/libraries/architecture/images/final-architecture.png up until such a time you fully understand your stuff and your app requires major refactor.
At such a point – move slowly to “Action Repositories” and you will never regret the time invested in learning Android
Good luck.
Hey Kenny,
Thanks for such an elaborated comment.
I think my main problem with this anti-pattern is exactly what you wrote: “the recommendation is purely for beginners, someone who has no clue where to start or just wants a guide on structuring their app better”. It’s better to not give any advice to beginners, rather than giving a bad one, but Google’s entire “architecture” in general, and their version of Repository specifically, are bad advices IMO.
I don’t agree that Repositories are analogous to, say, controllers in any way. However, even if you want to make this argument, then the presence of ViewModel, which is basically a controller, makes Repositories kind of rudimentary boilerplate, no?
Lastly, your idea of “Action Repositories”, which are “repositories that are responsible for one action”, sounds like a different name for use cases. Given that they are already named both use cases and interactors, I don’t think we need yet another term for the same concept. Or do I miss some important distinction here?
Hi Vasiliy
Sometimes people learn differently. This is important to understand for you as an instructor. Even at a degree course, you never learn patterns on your first or second year. You have to have something good and simple enough to get you started before you start to dive into more advanced and better practice topics down the line.
It’s like telling a 6 months old kid, the best way for humans to move from A to B is by walking or running. So let’s skip the learning to sit, crawl, etc and go straight to walking. Never gonna happen. Even if crawling is not the best way forward, all MDs will tell you it’s an important step to grasp in order to move better in the future.
Google, as a responsible parent, has to provide a simple enough entry point to the platform for a child. I would rather have a monolithic Repository that helps to explain the key concept that 6 other UseCase classes scattered everywhere that just adds to confusion to an already a very complicated subject.
I have nothing against your post. But authors like yourself are much better be mindful and try to appropriately label the level of the audience you are aiming to reach. I think if you started your post categorically as wanting to reach advanced beginners/intermediate levels – then maybe I wouldn’t have so much problem as this may (just may) help someone expand on the knowledge they have already acquired to solve an issue that maybe they are having with blotting repositories. Mind you, not all apps have to use that interface
Finally, as for “Action Repository”, my intention really was never to try and sell a book! I have my way of learning and understand things. I tend to relate topics to help me understand things better and I also tend to term things for my own understanding.
If I will ever write a book one day, I will surely try to stick to some standard naming! No offense to UseCases!
Kenny,
From what I can tell, you assume that this Repository anti-pattern is something that makes the life of beginner Android devs simpler. I disagree completely. Therefore, since we can’t agree on this fundamental assumption, I think we’ll need to agree to disagree in general.
Thanks for your inputs. It’s always good to have my ideas and perspective ctiticized.
100%. I say so because I know people who started there and quickly got to speed with Andorid app development and work with the Android platform in general.
I am not saying it’s the ALL-you-need android pattern for everything. Nothing is. I am saying, it has got so many people off the ground who are building interesting things with Andorid today.
Do they evolve the approach over time – surely. Everything evolves overtime and it’s credit to this approach that it allows you to gracefully branch out to patterns that work for you as you grow without loosing your hair
Anyway, I am big fan of you and I have taking a couple of your Udemy courses too! Keep up the good work
I mostly agree with both Vasiliy and Kenny.
First of all, thanks for the great article, it makes great points!
The thing where I rather side with Kenny is that using a repository as a beginner seems like a small evil that you can get out of relatively easily once you figure out you need to. I suppose that Google have tried to keep things simple, and put beginners in a situation that’s not too opinionated but generic enough to allow making improvements.
It would be nice though if they added more disclaimers and pointers for more advanced topics. It should be abundantly clear when the advised solution has compromises.
In regards to the article, I don’t have anything else to add because Kenny’s comment is very clear. I fully agree.
@Vasily, the idea of “Action Repositories” is just a possible implementation. I think the most valuable contribution of Kenny’s comment is that the implementation might be the anti-pattern. In some of my projects, for instance, I have
use casesthat execute the operations the app can perform. Those use cases can depend on one or more repositories. It’s not like repositories cannot be compatible with use cases.Using Google’s basic example as the evolution of the repository pattern in Android and make a claim on repositories being an anti-pattern could easily be misunderstood and become the kind of bad advice you shouldn’t give to beginners.
Hey Julian,
I think I made it clear in the post that there is a “valid” Repository pattern – the one described by classics. The problem with Google’s Repository is not the implementation, but the fundamental assumption that you can abstract out the difference between network and local persistence. This assumption is fundamnetally flawed, so there is simply no way to implement Google’s Repository pattern and not end up with non-optimal code.
I think my post is clear and nuanced enough, and, after reading and considering all the counter-arguments, I stil claim that Google’s Repository is an anti-pattern. The best course of action for any developer is to never go down that route.
You don’t need to agree, though.
Hey Vasiliy,
Fair point, you made it clear that there is a “valid” repository pattern and I should have acknowledged that in my comment.
Also, I agree with you that the repository pattern in Google’s example can be labelled as an anti-pattern and you clearly make your point. However, since article centred around Google’s example, the conclusion seems to generalise: “So, repository in Android evolved to become an anti-pattern…”. That is a part that can be misunderstood.
This is typical of a Kotlin anti-skills developer
Everything kotlin developers fail to use properly they call an anti-pattern (indeed, the reason kotlin was created was to stop those who fail at comp sci concepts from shooting themselves in the foot with basic syntax errors like break statements and increase the number of garbage web views that manage to make it as far as the app store)
Repositories are a good pattern, in the hands of a capable engineer. It’s never been an anti-pattern. Using something in the wrong way, does not make that something a bad thing. Needing to actually understand fundamentals, is not a bad thing.
I agree with this comment. The article describes an interface that is anything but a Repository, and then argues a Repository is an anti-pattern.
“Domain Driven Design Quickly” .pdf (free pdf), describes the repository pattern very well.
The author really should delete this article.
The article does not target the Repository pattern.
It targets the Repository pattern as understood and taught by Google for Android development.
Use cases is anti-pattern, not repositories. It’s much more organised to have containers/repositories grouped by functionality, than having literally thousands of classes all containing a single method. Any benefit you gain by use cases is completely lost in this much bigger drawback. If your repositories are too big simply group them into smaller ones like you also describe in the beginning of the blog, much better than having thousands of boilerplate classes and actually believing that’s good code.